My client receives external files from a vendor and wants to ingest them into the Data Lake using the integration pipelines in Synapse (Synapse's version of Azure Data Factory). Since the exact time the vendor sends the files can vary greatly day-to-day, he requested that I create a Storage Event Trigger.
I quickly set up the trigger:

Set Type to "Storage events", then select the correct storage account and container from the list associated to the current Azure Subscription. Use the blob path begins with setting to filter on the correct folder where the files land and use the blob path ends with setting to filter the file types (and perhaps file names if it's relatively consistent) to ensure that only the right blobs invoke the trigger. Finally, set Event to "Blob created".
Click Continue to go to the next page.
There will be a warning, "Make sure you have specific filters. Configuring filters that are too broad can match a large number of files created/deleted and may significantly impact your cost." which reminds you to check that the filters on the previous page actually return only the desired set of files. Be sure that you have at least one qualifying file in the folder and that the Data Preview can find it. If not, go back to previous page and adjust the the blob path begins with setting and the blob path ends with setting to correct the filtering.
Click Continue to go to the next page.
This final page asks for the pipeline parameters to use when the trigger is invoked.
Click Save to create the trigger.

Once the trigger has been saved, publish the data factory.
So far so good.
Then this popped up:
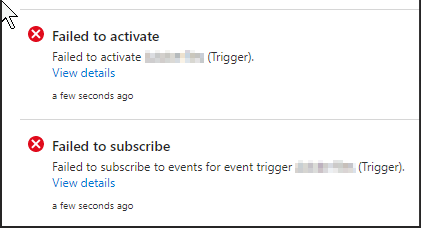
The trigger needs to create and subscribe to an Event Grid event in order to be activated. Even the error was mysterious:
"The client {GUID}' with object id {GUID}' does not have authorization to perform action 'Microsoft.EventGrid/eventSubscriptions/write' over scope '/subscriptions/{GUID}/resourceGroups/{resourceGroup}/providers/Microsoft.Storage/storageAccounts/{StorageAccount}/providers/Microsoft.EventGrid/eventSubscriptions/{GUID}' or the scope is invalid. If access was recently granted, please refresh your credentials."
I tried numerous searches on how to get the authorization to perform action Microsoft.EventGrid/eventSubscriptions/write and kept hitting dead ends.
Finally, I started poking around in the Subscription settings to see if something needed to be set in there. Under "Resource Providers", I found that Microsoft.Synapse, Microsoft.Storage, Microsoft.DataLakeStore and Microsoft.EventGrid were all registered. So that felt like a dead end.
After a bit more muddling around searching, I entered "Failed to Subscribe" in the search and found my savior: Cathrine Wilhelmsen. She had experienced exactly the same issue and had the same difficulty I had locating information on how to resolve issue. She even mentioned the same articles that I read in my attempts to figure out what to do! The only thing I had not done was visit the Microsoft Q&A thread about running event triggers in Synapse - probably because I stumbled upon her blog post first! Thank you, Cathrine!!
So what was the magic trick?
The Microsoft.DataFactory resource provider was not registered.
I hadn't expected that because we didn't have Azure Data Factory installed in this subscription, but now we know that it is required for event triggers.
Once the Admin registered Microsoft.DataFactory, I was able to successfully publish the storage event trigger. 😀

















